- 5 Jun 2002 - Mozilla
1.0 is released !!!! Xslf
repported me that:
Unfortunately, BiDi support on this release is not perfect yet.
The situation is worst on Mac OS.
Some notable bugs:
- Copy/paste of Hebrew text on Mac OS 9 is busted: bugs 119899,
- Text editing problems: 82352,
142233,
120334,
149811,
119860,
119857,
96057,
- Some layout issues: 123218
, 146135,
119882
- Ftang's bidi meta bugs: 115707,
115709,
115710,
115711,
115712,
115713,
115714,
115715
Also, the Hebrew mozilla l10n team (http://www.mozilla.org.il
) has started working, and it is reporting (in Hebrew) quite a
bit bugs about rtl User Interface...
Lina's comments are:
"Regarding the latest gfx code, forgot to mention one
important thing.
In the meantime, BiDi gfx changes ensure correct rendering
only on Win platform.
On all the other platforms, as I suppose, BiDi text would be
displayed correctly in the following cases:
- -- non-BiDi platform and visual text mode,
- -- BiDi platform and implicit text mode.
Also, the Windows specific code should be enhanced by checking
whether to reverse text on the basis of the embedding level,
instead of testing for the presence of Hebrew characters as
at present.
- Mar 30, 2000: Lina
Kemmel posts (on news:netscape.public.mozilla.layout) the
first release of the IBM code for review. This code has to be
installed on the M14 source tree. There are also some small additions
to XPCOM and an updated version of the Bidi engine that Simon
posted last week.
Summary of Bidi-related processing implemented in this code :
- Parsing: consume text token taking into account BiDi category.
- Retrieve "CSS display" part of the style sheet.
- Content model: resolve text classification of each token,
taking the CSS display property into account.
- Frame model: sort frames according to the resolved embedding
level of their content.
- Rendering context: ensure that the text is displayed in the
correct order.
- Mar 21, 2000: Simon
Montagu posted a BiDi reordering engine based on the IBM ICU.
- Mar 15, 2000 : Karl
Koehler agree in his
post to put his Unicode Arabic shape engine in LGPL - The
latest code can be found at http://titan.cs.uni-bonn.de/~koehlerk/u/
- This code is still in development for the Pango
(Gscript) project handled by Owen
Taylor.
- Feb 28, 2000 : Mike
Kaply post some
of the work that has been done for Bidi enablement. This is
a very good start. :-)
The Details and Diffs are available in the defect: http://bugzilla.mozilla.org/show_bug.cgi?id=24199
and the attachement changes enable the following:
- 1. Default alignment of browser can be set to right to left.
- 2. Scroll bars in browser windows, listboxes, and comboboxes
appear on the left.
- 3. New preference items (only default alignment is working)
- 4. New menus (not working)
To use this tar file, untar it in the mozilla directory (It overlays
files!) Then build it (Note that Bidi is turned on in config.mak
by definining IBMBIDI.)
- Feature Owner:
- Alexander Khalil <iskandar@ee.tamu.edu>
- Franck Portaneri <fportaneri[at]langbox.com>
- WinFE:
- Barak Ori <barak@comfy.co.il>
- XFE:
- Franck Portaneri <fportaneri[at]langbox.com>
- Mark Leisher <mleisher@crl.nmsu.edu>
- MacFE:
- Adil Allawi <adil@diwan.com>
starts an in-house project and might show a beta at the Gitex
show. He is open to a collaboration with the Mozilla team.
- XP:
- BI-DI : Michael Kaply <mkaply@us.ibm.com>,
Yaacov Akiba Slama <slama@il.ibm.com>
and Maha Abou El-Rous
- Arabic : Franck Portaneri <fportaneri[at]langbox.com>
and Mark Leisher <mleisher@crl.nmsu.edu>
- Hebrew : Dotan Dimet <dotan@usa.net>,
Ariel Backenroth <arielb@rice.edu>
- QA:
- Alexander Khalil <iskandar@ee.tamu.edu>
- Anoosh Hosseini <anoosh@gpg.com>
JKL <jklnet@usa.net>
Doron Shikmoni <doron@erez.cc.biu.ac.il>
Jonathan Rosenne <rosenne@qsm.co.il>
Dov Grobgeld <dov@orbotech.co.il>
Ariel Magnum <amagnum@bigfoot.com>
Shay Elkin <antil_za@mailandnews.com>
Roozbeh Pournader <roozbeh@sina.sharif.ac.ir>
- Document:
- Alexander Khalil <iskandar@ee.tamu.edu>
You want to participate :
- Visit on the mozilla.org site
and specially http://www.mozilla.org/community.html
- Subscribe to the netscape.public.mozilla.i18n newsgroup ( mailto:mozilla-i18n-request@mozilla.org?subject=subscribe)
- Have a look on the http://www.mozilla.org/docs/refList/i18n/scripts.html
and http://www.mozilla.org/docs/refList/i18n/schedule.html
- Download the source tree and build it on your system
- Contact the project owner by e-mail, cc mozilla-i18n@mozilla.org
to introduce yourself.
The main support is common for Arabic and Hebrew because of the
Bi-Di (Bi-Directionality) specificity of both languages.
Of course, the charset is not the same, as well as the latest rendering
process which is more complex for Arabic due to the "glyph shaping
determination". So, this part of the document is split in two sections
- Arabic and Hebrew :
Last Thursday, I held a meeting a design and code review meeting
regarding the Bi-Di code submission from IBM. Thanks to all those
who attended and sent me feedback. Here's a summary of where I
think we are today.
1. Architecture
The overall design of the new code is fine, as far as we can
tell. There are plenty of things that need to get fixed, but the
basic concept is perfectly acceptable. However, there were a few
issues that do need to be addressed before we could include the
code on the trunk.
A) platform-specific code
In general, we do not allow #ifdef PLATFORM code in XP modules.
You need to factor out the platform-specific portions of your
code, and isolate platform code in it's own module. Then the
build system can do the right thing at build time, without polluting
the XP modules with tons of #ifdef code. Along these lines...it
is absolutely *not* required that you implement Bi-Di on all
platforms. However, your implementation should strive to be
free of platform-specific assumptions, so that others can implement
it on their systems. Erik has volunteered to help validate your
design against other platforms (I think he volunteered to validate
Linux himself, and he "volunteered" Frank for Mac.)
B) illegal dependancies
You added a dependancy between layout and the view system that
isn't legal. Kevin Mcclusky can provide the details, but basically
you are making bad assumptions about frames in the view code.
Kevin, please elaborate.
C) misuse of interfaces
You have added concrete functions and member variables to several
interfaces. This is illegal. XPCOM interface are abstract contracts
that cannot include this sort of implementation. Also, you should
not have #ifdef blocks on an interface. An interface is a public
contract that sometime soon (probably Mozilla 1.0), will become
immutable. It cannot depend on compile-time switches. If you
need optional additional functionality, it has to be on a new
interface that is optionally a subclass of whatever concrete
class needs to support the methods.
2. Documentation
One thing that makes reviewing a submission of this size very
difficult is a lack of documentation. Some of the individual code
blocks are well documented, but there is no overview to guide
us. To get this code successfully integrated into the branch,
we need 4 levels of documentation:
A) an overview document.
This need not be long, or formal. Just something to help us
understand the philosophy behind the changes. Where are major
pieces of data stored (such as knowing whether Bi-Di is enabled,
or required for a particular page?) What classes do which portion
of the work? What work exactly is being done (i.e., frame reordering.)
I don't think the overview document needs to be complete and
polished before the code can go in, but I do think something
is needed before the next round of reviews.
B) interface documentation.
Though we're not always good at it, we do try hard to get all
major classes and public interfaces thoroughly documented. It
would be a big help if each new method had a comment block that
described what the method did, its arguments, it's return value,
and any possible side effects. We urge people to use a javadoc
syntax, because there are tools that automatically build documentation
from such comments. See nsIFrame.h for an example of a fairly-well
documented interface.
C) code-level documentation.
For the most part, the submission was pretty good about including
appropriate code-level comments. More is better, of course.
In particular, documenting the use of member variables inside
of classes is very helpful.
D) adhering to coding conventions.
Parts orf the submission were very poor at sticking to the
mozilla coding conventions. This makes the code much more difficult
to read. Please see http://www.mozilla.org/newlayout/doc/codingconventions.html
3. Performance
One of the biggest concerns is the impact on clients that are
not interested in providing Bi-Di support. Let's break this down
into several categories:
A) code size
Clearly, clients that are not interested in supporting Bi-Di
should not have to pay a significant penalty for the additional
code required for Bi-Di. The two ways we can think to minimize
the impact are to factor as much as possible into a separate
library, or to leave significant code chunks in #ifdef BIDI
blocks. I'd like to urge people to think about which code could
reasonably be factored into it's own library, since the support
costs for #ifdef code is high.
B) memory usage
Reading the code, it doesn't look like the Bi-Di code adds
any significant amount of bloat. We'll have to take measurements
once it's integrated to validate, but so far, it looks good.
C) performance
Most reviewers are less concerned with the performance of the
code when Bi-Di is required, than the impact of the code when
Bi-Di is not needed to lay out a page. There seemed to be a
few areas where Bi-Di code was being executed unnecessarily.
These could probably be fixed by simply checking whether anything
on the page warrented Bi-Di calculation before executing the
new code.
4. Implementation problems
There are plenty of minor problems that need to get fixed. Too
many to put in a newsgroup posting! But here are some general
trends:
A) memory leaks
There are a few places where you leak objects because of early
returns in a method. Using nsCOMPtr would prevent this.
B) null pointer checks
There are many places where pointers are used without first
being checked for null. These include new allocations, method
parameters, and returned out-parameters from function calls.
At a minimum, assertions need to be added to validate the pointer.
And unless you're guaranteed the pointer must be valid, you
should put in a null pointer check and return an error if null.
C) 64-bit compatibility
Chris Waterson noticed some code that seemed to make bad assumptions
about 32-bit pointers. We already have one 64-bit system, and
in general we strive to avoid assumptions about the hardware.
Chris, could you elaborate on the specifics here?
I'll foward individual comments separately.
Frank Tang propose that the priority should be :
- 1. Add XP bidi engine- grab from somewhere- free-bidi
or the pretty-good-bidi
Mark Leisher did
an excellent
comparison page here
- 2. Look at layout code- resolve directionality and break text
in different direction into different text frame.
- 3. Add directionality attribute into text frame
- 4. We already flow text frame depend on the DIR, so we probably
don't need to change that part.
- 5. Make sure the LTR text frame call GFX DrawString from left
to right
- 6. Fix GFX bugs.
| Detail Design: |
Find public source code or write new code from
scratch for the Bi-Di API |
Three codes are free or almost open source now. They are the
following in the order of their announcement:
Mark Leisher did
an excellent
comparison between these package results as well with IE
5.0.
However, under such systems, the GUI side (dialog boxes, text
input forms...) will behave only in Latin (no dual keyboard
management) - This pbm has to be fixed at the GTX level.
Here after is some details on these codes :
 19-Nov-1999:
Mark Leisher <mleisher@crl.nmsu.edu>
announces the Version 2.3 of the UCData package, which includes
the PGBA. 19-Nov-1999:
Mark Leisher <mleisher@crl.nmsu.edu>
announces the Version 2.3 of the UCData package, which includes
the PGBA.
What is the PGBA?
The PGBA is a small, simple, and fast one-pass Unicode bi-directional
text reordering algorithm that works "pretty good" for most
text. It provides an effective alternative to the Unicode Bidi
algorithm for implicit reordering of bi-directional text. It
does not currently support the explicit bi-directional codes
available in Unicode. Support for logical and visual cursor
motion through the reordered string is included.
Some problems with the PGBA have been fixed, speed has been
improved, the code has been reduced in size and made somewhat
clearer, a man page for the bidi API has been added, and the
documentation has been improved a bit. The README file in the
distribution details the changes. The home page will eventually
have a section showing the results from the PGBA, the IBM ICU
bidi implementation, and the FriBiDi implementation.
See http://crl.nmsu.edu/~mleisher/ucdata.html
for documentation and download.
7-Oct-1999 : Mark Leisher <mleisher@crl.nmsu.edu>
announced the availability of "Pretty Good BiDi Algorithm."
Version 2.1 to its UCData freeware package. The good news is
that Frank Tang did
the embedding of UCData 1.9 to the Mac, Win and Unix XPCOM in
April 1999.
Mark Leisher says: << ... This release provides some
bug fixes, and update for the new (apparently undocumented?)
Unicode 3.0 bi-directional categories, and the addition of the
"Pretty Good BiDi Algorithm." The PGBA is an elegant and simple
one-pass BiDi reordering algorithm that works pretty dang good
for most text. It has some deliberate, but (hopefully) minor
shortcomings just so developers who use it have something to
keep them occupied :-) The PGBA is in no way related to the
Unicode BiDi Algorithm except by coincidence.
IMPORTANT: The PGBA is dependent on UCData because
of the interpretation of certain 3.0 BiDi categories. To be
explicit, the following BiDi category assumptions are made
when building the character type data file:
- "AL" is equivalent to the "R" property.
- "BM", "NSM", "LRE", "RLE", "LRO", "RLO", "PDF" are
all equivalent to the "ON" property.
If your character type package of preference has these
assumptions, then using the PGBA will be no problem.
>>
Short and simple info page: http://crl.nmsu.edu/~mleisher/ucdata.html
The distribution is available in .tar.gz and .zip form from:
http://crl.nmsu.edu/~mleisher/ucdata-2.1.tar.gz
http://crl.nmsu.edu/~mleisher/ucdata21.zip
ftp://crl.nmsu.edu/CLR/multiling/unicode/ucdata.tar.gz
ftp://crl.nmsu.edu/CLR/multiling/unicode/ucdata.zip
3-Nov-1999:
Markus Scherer <schererm@us.ibm.com>
from IBM Cupertino mentioned that ICU
have the Unicode 3.0 BiDi algorithm implemented since the end
of september and since ICU 1.3. The current version is ICU 1.4.2.
Mark Leisher did some testing on it. If someone tried this BiDi
API, please send feedback on it.
15-Jan-1999 : Dov Grobgeld <dov@imagic.weizmann.ac.il>
announces the first alpha version of FriBidi, a Free BiDi library
that adhers closely to the Unicode BiDi algorithm. See http://imagic.weizmann.ac.il/~dov/freesw/FriBidi
for more info.
| Detail Design : |
Use an HTML Explicit or Implicit description of the RTL
management |
This part should determine if Mozilla Arabic support expects
that all the RTL/LTR management is done as :
- explicitly :
- i.e. only forced through <dir> HTML tags and directives
as described in HTML 4.0 proposal.
implicitly :
- i.e. meaning that if the charset definition is something
like :
- <META HTTP-EQUIV="Content-Type" CONTENT="text/html;
charset=iso-8859-6">
- then the default direction is forced to RTL (Right justification)
- both allowed :
- with the introduction of something like :
- <META HTTP-EQUIV="Content-Type" CONTENT="text/html;
charset=ISO-8859-6"> for Implicit
- <META HTTP-EQUIV="Content-Type" CONTENT="text/html;
charset=iso-8859-6-e"> for explicit
But this point should be in accordance with the HTML 4.0 definition.
Please send you feedback here, this is really an open subject
that need more input and discussions...
| Detail Design: |
Extend the Mozilla layout source code with
the Bi-Di API (By Franck Portaneri) - |
The API function calls must be embedded
within the Mozilla source tree to get the Bi-Di and Arabic support
build-in. This is a complex part where the following issues
must be taken in account:
- Dissociate the "Bi-Di" and "Glyph Shaping" process (to
allow both Arabic and Hebrew support)
- Work on full paragraph context (merge all text segments
of a paragraph in order to do the rendering process)
- Embed the "Output Rendering" process on the text display
level.
- Embed the "Text Selection highlight" process on the text
display level.
- Embed the "Mouse Position handling" process at the mouse
pointing level (for selection operation)
- Manage the full RTL presentation : Right alignment, Scroll
bar sliding reversed....
- Check the Printing subsystem and contribute with the
"UNIX Non-Latin1 Printing Enhancement" module owner.
- Take care to the coexistence with an BiDi Operating system
and avoid conflicts
| Detail Design : |
GFX code extension for Bi-Di (by Frank Tang) |
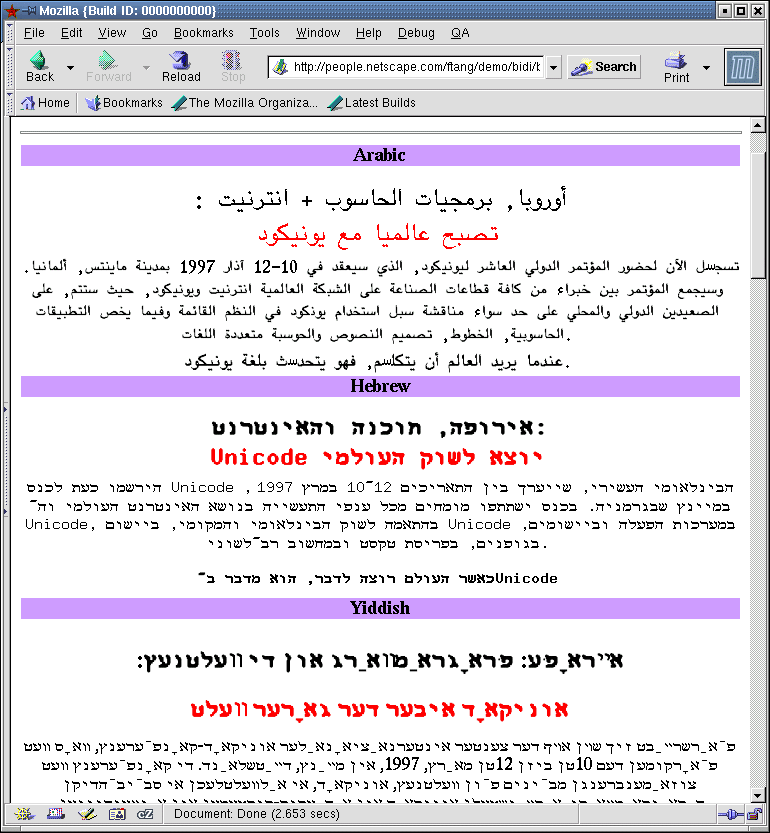
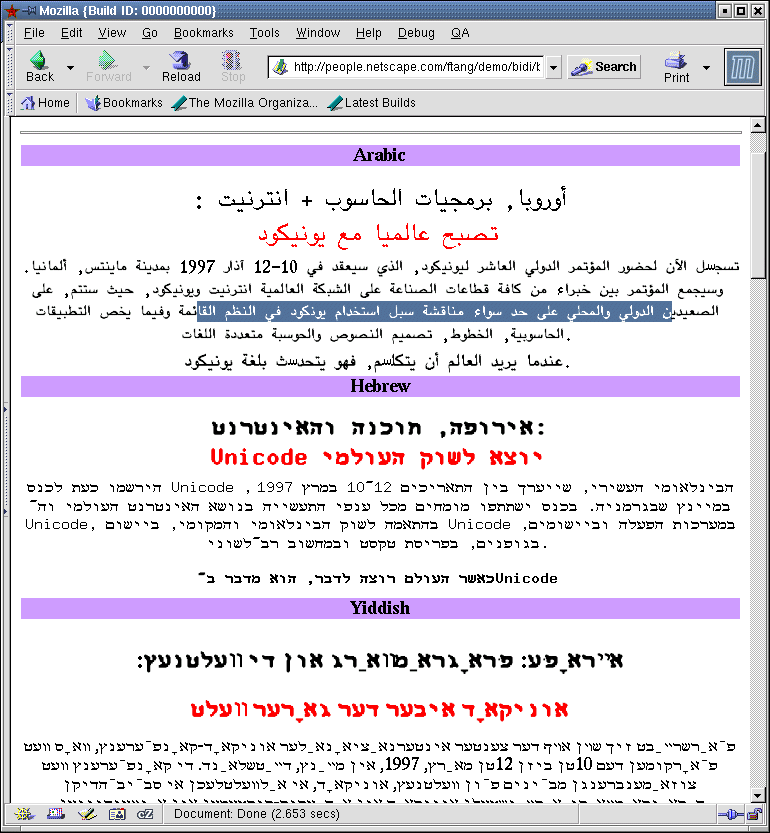
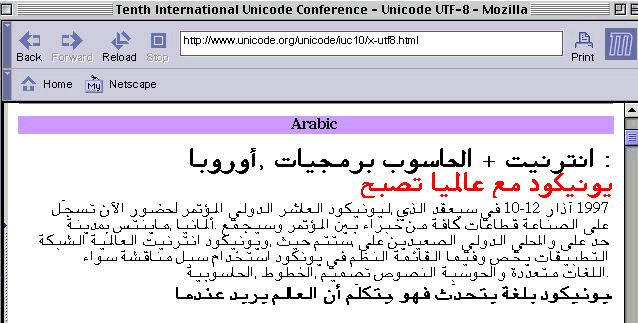
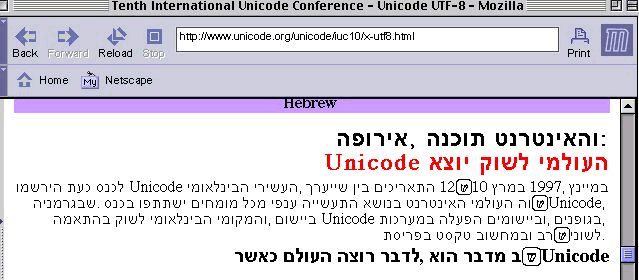
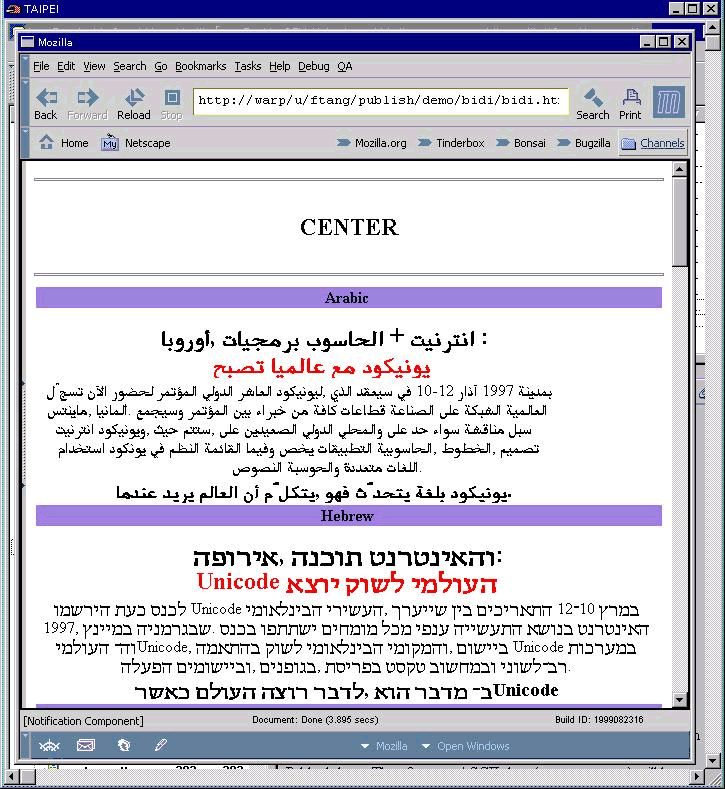
18-Aug-1999, Frank
Tang fixed some bugs on the MacGFX for Unicode BiDi
rendering. The Screen shot results are as follow :
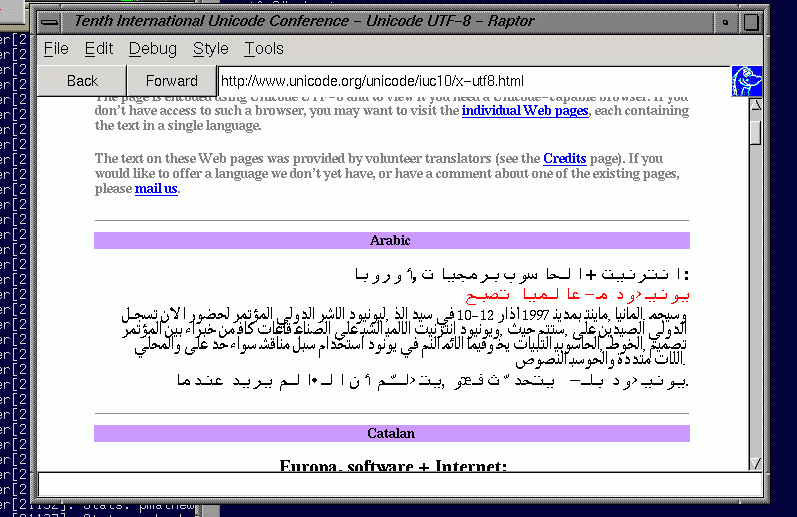
13-Sep-1999, Frank
Tang worked a lot on the WinGFX for Arabic
and Hebrew
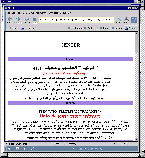
13-Sep-1999, The same code gives this
under a Linux machine and the LangBox Font
: Some bug have to be fixed in the Font Mapping.
To test this, try to use Mozilla to look at:
| Detail Design : |
Text Selection algorithm for BiDi (by Mark Leisher) |
The way we implemented it, the selection model depends on
whether it is being done in a visual or logical fashion.
The trick with doing visual selections is not to extend the
selection until a whole run of text in one direction has been
crossed. For example if we have the text LLLRRRLLL, starting
the selection in the left L section and dragging right will
not select the R section until the the right L section is reached.
- Problems: The selection can only cross directional
boundaries by including whole runs and implementation is a
little tricky.
- Benefits: This avoids multiple selection boundaries
and is behavior that some users expect.
Using the same text for logical selection, starting in the
left L section and moving toward the right, when the left side
of the R section is reached, the whole section is selected and
moving further right, the R section is deselected a glyph at
a time until the right L section is reached. At that point,
the whole R section is selected again.
- Problems: Strange selection highlighting behavior
that confuses users.
- Benefits: Can select portions of text across directional
boundaries, implementation is easier, and this is behavior
that some users expect (it is BTW, the way adopted on Arabic
enabled Windows).
Document Charset:
There are several charset commonly used on the web for Arabic/Hebrew
languages. We decide to support the following:
- Unicode : See http://www.unicode.org
- It is next generation charset standard : The new layout engine,
NGLayout, uses UCS-2 internally (in contrast to the current layout
engine which internally dealt with multiple encodings).
Mark Leisher <mleisher@crl.nmsu.edu>
is working on this specific issue.
-
- ISO-8859-6 : See http://www.langbox.com/codeset/iso8859-6.html
- It is international standard adopted by the Arab Community
as well under the UNIX X11 and Mac environment. It is common used
in many web site, such as :
- ASMO 449+ : See http://www.langbox.com/arabic/asmo449.html
- It is national standard and fully compatible with ISO 8859-6.
All sites using ISO 8859-6 are directly readable under this format.
However, some additional characters (Arabic digits, punctuation
signs... are added in this ASMO codeset)
- cp1256 : See
http://www.itsnet.com/~qamus/codepages/codepage_win95.htm
- It is the code page Window used for font, and supported by
many web site, such as most of site developed or hosted under
Arabic Windows machine...
- Arabic-Mac Code Page (Is there a specific name?) See
http://www.itsnet.com/~qamus/codepages/codepage_mac.htm
- It is the script code Macintosh used, it is compatible with
ISO 8859-6 and ASMO 449+.
IRAN SYSTEM : http://sina.sharif.ac.ir/~roozbeh/farsiweb/iransystem.txt
Apparently, more than 90% of Persian pages on the internet are
stored in this character set.
ISIRI 3342 : http://sina.sharif.ac.ir/~roozbeh/unicode/3342.txt
- It is a Farsi codeset, not yet adopted by ISO, but by the Iranian
Group of Normalization. It is also used on the Web with the PMosaic
browser. It is the actual 8 bit standard for Farsi. The Farsi
language cannot be managed by the ISO 8859-6 alone.
Mail Charset:
We decide to use ISO 8859-6 as Mail Charset since it is de-facto standard
common to all platforms.
Front-End Font Encoding
- For Arabic, there not really a Font Encoding definition, just
because even if the codeset have been defined and fixed, the font
itself must include much more glyphs than can appear in the codeset.
This is due to the "glyph shaping" characteristic of the Arabic
language. So according the different Software implementation,
we can find different font set definition. At LangBox, we
used to have 2 levels of font encoding, according to the device
font capabilities and the requested quality :
- As for example, to read text on the web, the second set is
quite enough. Now for publishing or printing purpose, it is preferable
to use the first one. Some ISO-8859-6-8 fonts are given
with the AraMosaic browser on UNIX, and can be used with Mozilla.
- So, we propose the following :
- XFE
- ISO-8859-6-8
or ISO-8859-6-8X
(includes more shapes in a 8 bits font)
- WinFE
- Arabic Windows fonts (used under Arabic Windows license) -
Or any Free TTF fonts (any pointer here???)....
- MacFE
- Arabic Mac fonts
- Printing
- ISO-8859-6-16
Host Operating Systems Consideration:
There is two types of host operating systems :
- Standard (English) Operating Systems: (e.g. without any Arabic
specific add-on) :
On these systems, the Bi-Di process must be done by Mozilla to
display correctly HTML document, but all Operating System GUI
will behave in Latin only (for <select...> , <textarea...>
or <input...> fields in forms, or for dialog box such
as Edit/Find in Page...).
The fontset must also be provided by Mozilla here.
- Arabic Operating Systems : like Arabic Windows, Arabic MAC,
or Arabic Language Module on UNIX
On these systems, the Bi-Di rendering process is already done
within the XDrawString() (UNIX X11) or TextOut() (Windows) functions,
and there is a potential risk that the Bi-Di process can be performed
twice on the same string. This is not correct and will give garbled
output. So there is two options here:
- Disable the OS Bi-Di process from Mozilla before display
text in the HTML page (preferred)
- Just pass the original logical strings to the OS functions,
but there in this case, the OS Bi-Di engine parameters (global
direction, numeric type, diacritics, fontset...) MUST be the
same as those assumed by the Mozilla Bi-Di engine.
The advantage to use an Arabic OS is that all GUI widgets and keyboard
input will also work properly in Arabic. The System Arabic fonts could
be used, or new font can be add, but according the same fontset that
the system's one.
Detail Design : Introduce the Arabic new Charset :
See the Frank Tang doc : How To Add Additional Charset :
http://www.mozilla.org/docs/refList/i18n/addcharset.html
This part has been directly created from the Dotan Dimet document
: "A Proposal For Preliminary Hebrew Support In Mozilla" (URL??)
where I made some light modification (Please Dotan, send me your
comments)
Document Charset:
There are several charset commonly used on the web for Arabic/Hebrew
languages. We decide to support the following:
- ISO-8859-8 :
- This is an VISUAL standard (according RFC1555)
: Apparently, 98% (??? to be verified) of Hebrew language documents
on the Internet use the webfont or visual encoding to display
hebrew. This codeset is the same as ISO 8859-8-i, but the Bi-Di
rendering process has already be done on the stored data within
the HTML document. Thus, the Bi-Di process must NOT be done a
second time, and we just have to display the data as is, using
an ISO 8859-8 font set. This support should be very easy to implement
and if there is really so much site that use it, it must be done
first. However, the data cannot be used for editing purpose since
the input sequence is lost.
- It is common used in many web site, such as :
(any URL here...)
ISO-8859-8-i :
It is international standard adopted under the UNIX X11, Windows
and Mac environment. It is used in web site, such as :
(any URL here, guys...)
This codeset is an IMPLICIT codeset, meaning that the rendering
process has to follow the Bi-Di algorithm to re-organize both
Latin and Hebrew letters.
ISO-8859-8-e:
EXPLICIT encoding: apparently not used
CP-1255
Default under Hebrew Windows -
Mail Charset:
We decide to use ISO 8859-8 as Mail Charset since it is the standard
to all platforms for data exchange (RFC 1555).
Front-end Font Encoding
- XFE
- ISO-8859-8
- WinFE
- ISO 8859-8
- CP-1255
- MacFE
- ISO 8859-8
Detail Design
By Dotan Dimet (Email: dotan@usa.net
) (Modified by Franck Portaneri <fportaneri[at]langbox.com>
- Dotan, any comments???):
1 - Support of Hebrew Visual : This means adding support
for "visual" display of the iso-8859-8 charset.
Currently, most of Hebrew language documents on the Internet use
the webfont or visual encoding to display Hebrew The Visual encoding
method does not rely on the OS or windowing environment for Hebrew
support. In fact, it actively ignores such support by requiring
the user to install special fonts and the page creator to write
his Hebrew text in reverse (if he's using an application with Hebrew
support) and use HTML tags such as PRE and NOBR to handle line-breaking.
Despite the hassle, this lowest common denominator de-facto standard
is in such wide use that it has been ratified officially, and Israeli
standard bodies have determined that the following META tag should
be used to label such pages:
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=ISO-8859-8">
Mozilla doesn't recognize this tag. Or rather, when it sees it,
it sets the encoding to "Western (iso-8859-1)", and treats the Hebrew
text as a standard (Western) 8-bit character set, without applying
any Bi-Di algorithm. However, if the special "web fonts" are chosen
for this encoding, the pages will be readable.
Problems with this method include line-breaking (must be controlled
by HTML tags, must not be done automatically by the display), printing
(on systems with Hebrew support the BiDi algorithm kicks in, reversing
text), and font choice (the limited selection of special web fonts
is rather ugly).
The two big advantages of this method is that it should work on
systems without any built-in Hebrew support, and that is the de-facto
standard.
The suggestion is to add support for this charset to the user interface.
Instead of overriding the "Western" encoding, the user should have
a separate entry for "ISO-8859-8 (visual)" where he can install
his web fonts. A good improvement to this would be to bypass font/language
association, and let the user use any installed Hebrew fonts to
view pages. This in fact is what the Hebrew version of Internet
Explorer allows you to do. You'll still need to install fonts if
your system has no Hebrew support (and you'll still probably see
the page title and any form elements as messed up), but if you have
a Hebrew-aware system, you'll get more choice.
The second level of this "Visual" support should be to make it
available on Hebrew Operating systems by either disable the System
Bi-Di rendering in the TextOut (or equivalent) function, or by performing
a reverse-transformation on the Visual line to get back the logical
(Implicit) one and let the OS render it correctly (but a little
bit tricky and resource consuming).
2. - Support Hebrew Implicitly: This means adding support
for the logical or "implicit" interpretation of ISO-8859-8 Documents
written in this method will not be reversed when viewed with applications
that DON'T have an Hebrew support, it will be shown in the inputting
order. The charset tag used should be"iso-8859-8-i", and the Bi-Di
algorithm should be used to present this text. It consists in the
support for codes that implicitaly set the text's direction (e.g.
Latin, digit or punctuation mark characters are considered as LTR
("Left-To-Right") direction characters, while Hebrew characters
are considered as RTL ("Right-To-Left") In fact, the Implicit coding
represents and store the exact entry sequence of keys pressed by
the user when he/she wrote the text. The support of this encoding
is necessary for text editing.
On operating systems with Hebrew support, this implicit support
is already there, and the Hebrew text will be displayed correctly,
but without Bi-Di support within Mozilla, the text selection for
cut/paste operation, mouse pointing will not work properly. But
here, we should take care that the Bi-Di process is not performed
twice on the same line (in Mozilla and in the OS TextOut (or equivalent)
functions).
On standard (English) Operating systems, If you use a font that
the system knows is Hebrew to look at some text in the browser,
it will be displayed the way it was written (and then cannot be
read correctly)
3 - The Fiddly Bits: These include support for tricky directionality
codes, HTML 4 stuff, CSS(?), Forms, and Javascript.
4- The support of Hebrew Explicit: This is really an optional
case. Apparently, it is not really used for Web document, unless
someone can explain or gives some input here : It consists in the
support for codes that explicitly set the text's direction (codes
that exist in ISO-8859-8 and Unicode, as well as those in HTML 4)
and that should be included to force specific nested LTR or RTL
sub-string within a line. The Bi-Di algorithm's should attempts
to interpret these codes and by-pass the implicit ordering of characters
to render its output text. The charset tag used could be "iso-8859-8-e".
Reference
and Related Specification
|
W3C Documents:
RFC:
Character Sets:
- Unicode 3.0
- ISO 8859-6:1987
- ISO 8859-8:1988
- Code Page 1255 Windows Hebrew
- Code Page 1256 Windows Arabic
- Macintosh Arabic
- Macintosh Farsi
- Macintosh Hebrew
- Code Page 862 MS-DOS Hebrew
- Code Page 864
- Code Page 708 MS-DOS Arabic ASMO [ same as ISO 8859-6]
- IRAN SYSTEM
- ISIRI 3342:
- ISIRI 2900:
- ASMO 449+: [superset of ISO 8859-6, underset of Arabic MAC]
- Importance: Unknown
- Specification: [Needed]
- Unicode Mapping: [Needed]
MIME Charset Name
Related Engineering Information:
Related Information and Resources:
- Any URL, pointer...??
- How to desactivate or bypass BiDi system routines under Bi-DI
OS (Arabic Mac or Windows for instance)
BiDi Algorithm Code
XFE fonts:
- http://www.langbox.com/bidimozilla/fontXFE
(See README file)
To be determined ... |