{kind=link}
The Arabic script presents major and specific processing problems that are not encountered in Latin based languages, or even in Far east languages. The Software localization process cannot be handled directly by regular MNLS (MultiNational Language Supplement) architecture support which is available on most UNIX systems for European languages. Specific "Internationalization" support must be added either to the Application itself or, and this is the objective to LangBox International's products, to the Operating system interface. The main Arabic language support problems are the following: character codeset and standard encoding, character shaping and text direction algorithms, character fonts, Global screen direction and mirror effect, numerals and Hindi digit shapes, Arabic vowels and collating sequences, neutral characters, dual keyboard management, and optical character recognition,
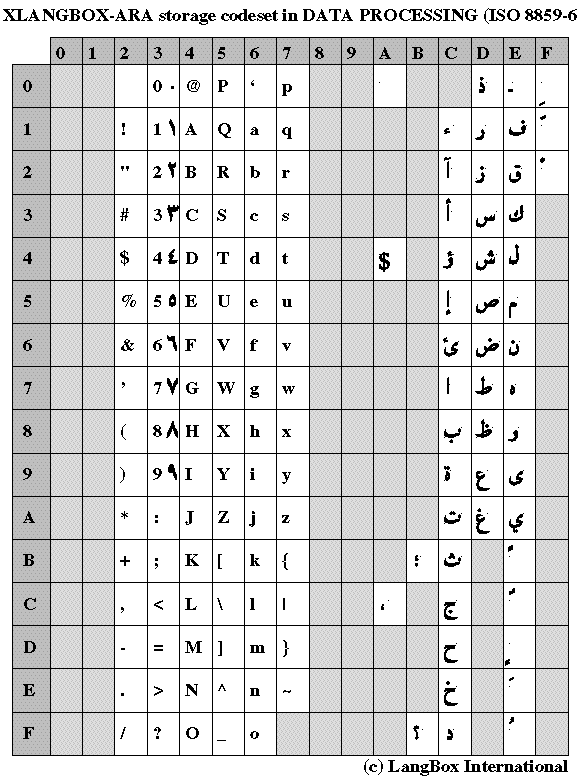
The recommended codeset used for representing Arabic script under the UNIX environment is ISO 8859-6 (the same as ECMA 114 and ASMO 708). Several other codesets exist on the PC environment or in constructor specific implementations (IBM, WANG...), and codeset converters to or from these codeset to ISO are then needed. The alphabet of Arabic language is well defined. Each letter receives one ISO character value. However, this ISO 8859-6 codeset is incompatible with other languages covered by the ISO 8859 family (European, Cyrillic, Greek,...) since it is an 8 bit codeset. Data stored in the Arabic codeset cannot be displayed on a regular ISO 8859-1 or Latin 1 based system. This problem can be solved with extended multi-byte standards such as Unicode. Also, and this is the case for European localization as well, ISO 8859 is an 8 bit codeset, meaning that the application must be 8 bit clean. The 8 bit support of applications was a problem with old software initially designed for ASCII support and the US market. Most UNIX applications now support 8 bit code sets.
The graphic form (glyph) shown in the ISO 8859-6 character chart is not the identity of that character (like in Latin 1 for example). The same Arabic character may correspond to up to four different glyph types. The glyph type of a character depends on the position of the character within a word. The possible glyph types are: the Beginning shape (a character that begins a word), the Middle shape (a character that is surrounded by other Arabic characters), the End shape (a character that is located at the end of a word) and the Standalone shape (a character that is surrounded by whites paces).
Some characters can be linked to another character on either side, (each character has four possible glyphs), some characters can be linked only on their right side (and have only two possible glyphs) and some characters cannot be linked on either side (and have only one possible glyph).Also, in some character sequences, the formation of ligatures is obligatory. These ligatures associate one specific character form to the joining of two Arabic characters. They are necessary for well-rendered Arabic text. In addition to this, Arabic text is written from right to left, and mixed Arabic/Latin strings include text in both directions which is presented on the same line. In fact, text is stored in sequential order in the backing store. Logical or backing store order corresponds to the order in which text is typed. The conversion from backing store format to the readable one represents one of the major problems in the processing of Arabic script. In order to be the most useful, powerful and especially transparent regarding applications, this conversion must be handled by low-level text rendering routines.
The Arabic character font also has another particular need. Arabic is always written in "cursive" or "handwritten" form, where characters are linked together as if they where written by hand. The linking rules are well defined, but the font needs to be adapted to this style, and the display device must be able to join all characters designed in order to avoid blank columns between characters. The nicest solution is to use proportional width fonts which are very important for rendering Arabic script. Some devices, such as alphanumeric terminals, cannot handle this kind of font, and use fixed width fonts instead; the result is less enjoyable but remains readable.
Due to the Right to Left writing direction of the Arabic language, the common way to read a document is to start from the top right-hand corner. This is also the case for an application screen or a printed document. This characteristic of the Arabic language is also a problem for standard applications. These applications are designed for Latin based character sets which have built their screens starting from the top left-hand corner position. Also, several little details, such as the menu cascading in a GUI (Graphical User Interface) application, need to be right to left oriented. These characteristics are very difficult to localize if they are not included in the original design of the software.
Numerals are mainly handled in the same way as Latin languages. Numbers are read from left to right with the highest order digit on the left side. However, there are two possibilities for numeral shapes. In North African countries, the digit's glyphs are the "Arabic digits" (i.e. the same as for Latin use). In Middle Eastern countries, the digits used are the "Hindi shapes." The display of one of these two possible digit representations must be user configurable.
The Arabic vowels (named "Tashkil") have a specific status in Arabic text. In fact, in common use, these characters are simply not used and Arabic text is written only with consonants. Any possible synonym confusion is cleared according the context. However, in some cases (e.g. official or legal documents), vowels may be added to the text. These vowels look like Latin accents that are displayed above or below a consonant letter. The problem here is that from a collating sequence or a pattern search point of view, a word with vowels and the same word without vowel must have the same intrinsic value. Also, text input with vowels must be displayed or printed with or without vowels.
Normally, Arabic characters are always written from right to left, and Latin characters are always written from left to right. For some technical reasons and in order to be able to display text correctly in right to left mode some application screens or forms are initially built in a left to right direction. Some characters must be able to take the global writing direction despite their own direction value. It is necessary then to define a set of neutral characters which are able to use the global writing direction when being written.
In most cases, European language keyboards have one specific keyboard layout, including all needed Latin letters. Since the Arabic alphabet is different from the Latin character set and because a user must always be able to input Latin and Arabic characters from the keyboard (ISO 8859-6 includes both ASCII and Arabic characters), a dual keyboard management system is needed. The keyboard management system must allow the user to switch from one language to the other using a single keystroke. This is also the case for languages that use Cyrillic, Greek, or Thai character sets.
In order to be coherent, the solution must include either an engraved keyboard with both ASCII and Arabic letters on each key, or to be more flexible, a set of keyboard stickers to be installed by the user on the existing keyboard. Sometimes the second solution is not acceptable to users and it is necessary to supply an engraved keyboard.
.
Because Arabic is a connecting letter language, it is quite difficult to use the same method and algorithms for Optical Character Recognition as for Latin languages. The main problem is the ability to extract a single letter from a word.
One of the most difficult points of the Arabic writing culture is the ability to reproduce cursive handwriting aspect of the text on a computer screen or within an application. Initially, with "character based" interfaces such as typewriters, dump terminals and dot matrix printers, results where acceptable, but were not appreciated by all users. This kind of interface always uses fixed width fonts and, even when "context analysis" and "automatic shape determination" are implemented, the final rendering (on a screen or on a printed document) is not high quality.
Since the appearance on the market of graphical interfaces (such as Microsoft Windows on PCs and X Window on UNIX platforms) and the ability to use proportional width fonts and WYSIWYG (What You See Is What You Get) systems, the rendering of Arabic text on a screen or on a PostScript printer more closely reflects user expectations.
Some Arabic standards, like the keyboard layout, are conflicting and are not always clear. The ASMO, standards organization for Arab countries, has determined a specific layout, but user habits have developed from the use of specific manufacturer products different standards. For example, regarding the ligature "Lam-Alef," this ligature (visual shape coming from the juxtaposition of two ISO letters "Lam" (L) and "Alef" (A)) appears on an IBM keyboard standard. To be compliant, Microsoft has also implemented this same solution. Since this character does not exist "as is" in the ISO codeset, the ASMO layout does not include this key, and most users find this unacceptable. In fact, this problem is due to market competition rules that give a de-facto standard to the first solutions. The localization of an application must also take into account these kinds of problems.
Arabic writing is the same for all Arab countries. However, the speaking of Arabic may be different and therefore different country's must be implemented. This is the case for month names, which are different in North Africa, around the Nile Valley area and in the Middle Eastern countries.
Abbreviations and acronyms (like IBM for International Business Machine, NY for New York or PM for time indication) do not exist in Arabic. We always need to specify a complete word. This characteristic needs to be taken into account when translating messages and labels of user interfaces into Arabic. The length of messages will grow. In some cases, the real visual length of labels and message should be greatly reduced using a proportional width font. One of the characteristics of Arabic cursive writing is that the beginning and the middle shapes are more narrow than final or isolated shapes. The result of a normal string is very condensed.
The general behavior of some applications is not directly applicable to Arabic language usage. This is typically the case for word processing and their justification features. The standard algorithm to justify text in Latin is to add spaces between words on the line in order to achieve both left and right alignment. The method used for text justifying in Arabic is to stretch the last letter of a word in the line. This stretching is called keshide, and to be fully compliant with the Arabic culture, a word processing must implement it.
As explained above, the DOS market created most of the Arabic implementation standards. Microsoft Arabic DOS and Arabic Microsoft Windows have reinforced more again this aspect. A user moving from this kind of environment to a UNIX environment will expect to find the same Arabic features and uses. However, after initial discontentment, users will normally adapt themselves to a new system.
Some of these PC solutions could not be implemented on the UNIX environment. For example, in Arabic DOS character applications, users press Right Shift+Left shift to toggle their keyboard layout between Arabic and Latin mode. If you press the same key sequence on an alphanumeric terminal (such as VT100 or Wyse), the UNIX operating system and therefore the application will simply receive nothing from the serial line connection. Hence, it will be unable to use this sequence to switch between two internal logical keyboard mappings.
Also, during the past thousand years, a number of Arabic calligraphic styles have grown in popularity and are in standard use today. The most famous Arabic calligraphic styles are Naskhi, Baghdadi, Farsi, Kuffi, and Requah.
... In fact, to be transparent, the cut and paste internal X Server buffer must get an internal consecutive data area in one block. This is not straightforward on mixed Latin/Arabic string, where the internal order is completely different from the visual order.
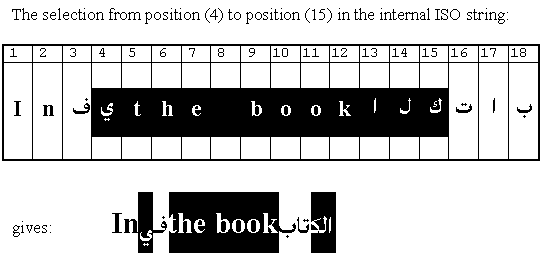
For example, in the following string, the first table shows the stored Arabic data (in their logical order) and the result of an highlighting action from charcter 4 to 15 gives 3 independant highlited area on the rendering string :
This attribute splitting is not automatically done by the regular Motif library, and a specific enhancement is needed. In the same way, any cursor pointing using the mouse within an Arabic text also needs to be converted to an internal pointing position to enable transparency for editing actions. The correspondence between the internal buffer structure that follows the ISO codeset and the Visual buffer that depend on the Arabic context must be checked and always highly valid.
...
Biographies:
Franck Portaneri graduated from the University of Nice Sophia Antipolis, France, and received MS Degree in computing. He worked in the conception of the first bilingual Latin/Arabic UNIX Operating System. He has been working in the multilingual field since 1986 and leads several internationalization and localization projects. He is the author of several publications dealing with UNIX localization.
Fethi Amara graduated from the University of Nice Sophia Antipolis, France, and received MS Degree in computing. During his Ph.D., he worked at INRIA (National Institute of Research in Informatics and Automatics) on multilingual Desktop Publishing within the MALIN Project (MultiAlphabetism and Lingualism in Informatics). He joined the LangBox team in 1990. He is the author of several publications dealing with multilingual user interfaces.